2026世界杯
九游会app下载 万字拆解Prompt Engineering的进化史: 从手工调优到自动优化
发布日期:2026-03-05 13:12 点击次数:204

本文深入剖析教唆工程从Zero-Shot到Chain-of-Thought、Tree-of-Thoughts,再到APE、OPRO、DSPy等自动优化技艺的演进历程,解读这场静默但真切的AI交互范式翻新。

2020年,当GPT-3横空出世时,东说念主们骇怪地发现,只是通过改变输入的措辞,就能让并吞个模子阐扬出判然不同的才气。这种通过经心设想输入来辅导模子输出的技艺,被称为PromptEngineering(教唆工程)。
五年往时,PromptEngineering也曾从一门”玄学”发展成为系统化的工程学科。从起始的手工调优,到想维链(Chain-of-Thought)的引入,再到想维树(Tree-of-Thoughts)的探索,直至今天自动教唆优化(APE、OPRO)和编程式教唆框架(DSPy)的兴起——教唆工程正在资格一场从”艺术”到”科学”的范式出动。
这场变革的中枢驱能源是什么?
谜底很浅易:效能与规模化。
手工设想教唆词耗时耗力,且难以复用。当企业需要将大模子应用于数百个不同场景时,手工调优的形式显豁无法例模化。自动教唆优化技艺的出现,让机器大略自动发现最优教唆,大大裁汰了应用门槛。
这场变革不单是是技艺层面的创新,更是对通盘AI应用诱导范式的再行界说。在往时,诱导者需要破耗多数期间调试教唆词,尝试千般措辞和体式。而当今,自动优化技艺可以在几分钟内找到比东说念主工设想更好的教唆。这种效能普及将极地面鼓吹大模子在各个行业的应用。
同期,教唆工程的发展也正在改变东说念主机交互的形式。从敕令行到图形界面,再到当然谈话交互,教唆工程正在成为新一代东说念主机交互的中枢技艺。将来的用户可能不需要学习复杂的软件操作,只需要用当然谈话刻画需求,AI就能自动完成任务。
本文将带你穿越这场PromptEngineering演进的期间线,深入融会:
Zero-Shot和Few-Shot教唆为何能成为基础范式?
Chain-of-Thought如何开启推理才气的新篇章?
Tree-of-Thoughts如何模拟东说念主类的多旅途想考?
自动教唆优化(APE、OPRO)如何兑现教唆的自动发现?
DSPy等编程式框架如何再行界说教唆工程?
通过本文的阅读,你将系统性地了解PromptEngineering从出身到教训的完好历程,掌合手千般教唆技艺的道理和应用场景,为推行职责中的大模子应用打下坚实基础。
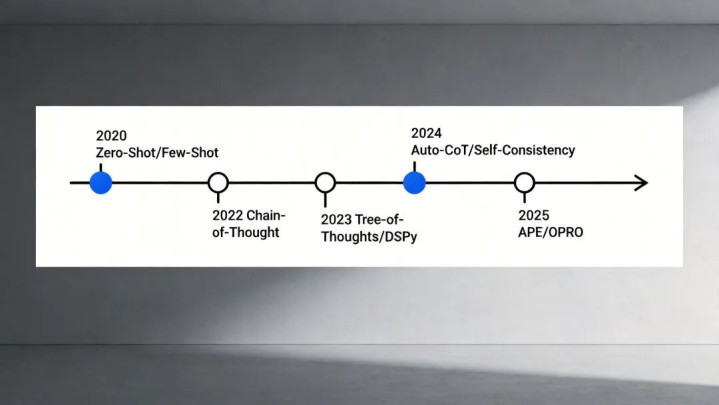
图1:PromptEngineering演进期间线(2020-2025)
一、基础范式——Zero-Shot与Few-Shot
1.1Zero-ShotPrompting:零样本教唆
Zero-ShotPrompting(零样本教唆)是最基础的教唆形式,即平直向模子建议问题,不提供任何示例。这种形式依赖于模子在预测验阶段学到的知识。
Zero-Shot的中枢假定是:模子也曾通过海量预测验数据学会了千般任务的”模式”,只需要通过适应的指示就能激活这些才气。
示例:
输入:将以下汉文翻译成英文:”今天天气很好。”
输出:”Theweatherisnicetoday.”
Zero-Shot的上风在于浅易平直,无需准备示例。但过错也很显豁:对于复杂任务,模子可能无法准确融会任务条款,导致输出质地不褂讪。
在推行应用中,Zero-Shot适合那些模子在预测验阶段也曾充分学习过的任务,如浅易的翻译、撮要、分类等。但对于需要特定体式输出或领域知识的任务,Zero-Shot每每阐扬欠安。
为了普及Zero-Shot的后果,计算者建议了一些技巧:
脚色设定:在教唆中明确模子的脚色,如”你是一位资深翻译各人”
任务刻画:详备刻画任务要乞降输出体式
分步指示:将复杂任务理会为多个顺次
1.2Few-ShotPrompting:少样本教唆
Few-ShotPrompting(少样本教唆)通过在教唆中提供几个输入-输出示例,让模子”学习”任务的模式。这种形式运用了大模子的潦倒体裁习(In-ContextLearning)才气。
2020年,OpenAI在GPT-3论文中初度系统性地展示了Few-ShotLearning的威力。他们发当今某些任务上,仅需提供几个示例,GPT-3就能达到以致超过有意微调模子的后果。
示例:
输入:将以下汉文翻译成英文:
汉文:你好。
英文:Hello.
汉文:谢谢。
英文:Thankyou.
汉文:今天天气很好。
英文:
Few-Shot的关节在于示例的选拔。计算标明,示例的质地、千般性、限建都会影响模子阐扬。一个好的Few-Shot示例应该:
明晰明确:输入和输出的对应联系一目了然
笼罩畛域情况:包含千般可能的输入类型
体式一致:整个示例罢黜调换的体式
对于示例的数目,计算标明不时3-5个示例就能取得可以的后果,过多的示例并不一定能带来更好的性能,反而会增加token虚耗。示例的限定也有影响——将最明晰的示例放在前边不时后果更好。
此外,示例与测试样本的相似度也很抨击。若是示例与测试样本在语义上更接近,模子的阐扬不时会更好。这启发了自后的动态示例选拔技艺,即笔据输入动态选拔最关联的示例。
在推行应用中,Few-Shot教唆的设想需要探讨多个身分。起始是示例的质地——示例应该明晰、准确、有代表性。其次是示例的千般性——应该笼罩任务的千般可能情况。终末是示例的限定——不时将最明晰的示例放在前边后果更好。
1.3Zero-ShotvsFew-Shot:如何选拔?
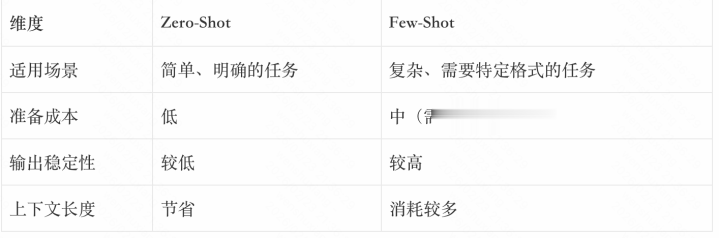
在推行应用中,建议先从Zero-Shot脱手,若是后果不睬想,再尝试Few-Shot。对于需要严格输出体式的任务(如JSON输出),Few-Shot不时是更好的选拔。
二、推理翻新——Chain-of-Thought
2.1想维链的出身
2022年1月,Google计算院的JasonWei等东说念主在论文《Chain-of-ThoughtPromptingElicitsReasoninginLargeLanguageModels》中建议了Chain-of-Thought(CoT,想维链)技艺,开启了教唆工程的新篇章。
CoT的中枢想想是:让模子在给出最终谜底之前,先生成中间推理顺次。这雷同于东说念主类管制复杂问题时的”草稿纸”想维——咱们不会平直写出谜底,而是先一步步推导。
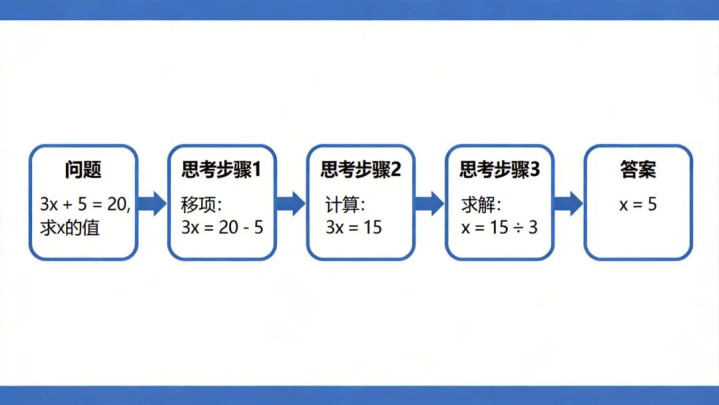
图2:Chain-of-Thought想维链暗示图
2.2CoT的职责道理
CoT通过在Few-Shot示例中加入推理过程,辅导模子生成雷同的推理链。
圭臬Few-Shot示例:
Q:罗杰有5个球,又买了2罐,每罐3个球。他当今有几个球?A:11
CoTFew-Shot示例:
Q:罗杰有5个球,又买了2罐,每罐3个球。他当今有几个球?A:罗杰脱手有5个球。2罐每罐3个球,共6个球。5+6=11。谜底是11。
当模子看到带有推理过程的示例后,它会师法这种作风,在讨教新问题时也先生成推理过程,再给出谜底。
2.3CoT的后果
{jz:field.toptypename/}论文高傲,CoT在多个推理基准上带来了权臣普及:
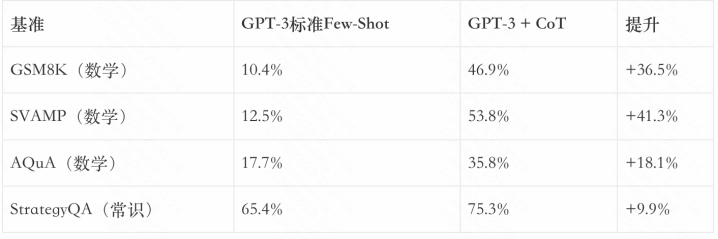
CoT的后果在大型模子上尤为显豁。计算标明,模子参数目需要达到约100B,CoT才能施展权臣述用。这教唆咱们:CoT需要模子具备充足的知识容量和推理才气。
CoT的成功不仅在于普及了准确性,还在于增强了可解释性。通过检察模子的推理顺次,咱们可以融会模子是如何得出论断的,这对于调试和改造模子颠倒抨击。若是模子在某个顺次出错,咱们可以针对性地改造教唆,辅导模子朝正确的办法想考。
2.4Zero-ShotCoT:无需示例的想维链
2022年5月,Kojima等东说念主在论文《LargeLanguageModelsareZero-ShotReasoners》中建议了Zero-ShotCoT技艺。他们发现,只需要在问题后加上一句”Let’sthinkstepbystep“(让咱们一步步想考),就能触发模子的推理才气。
示例:
Q:罗杰有5个球,又买了2罐,每罐3个球。他当今有几个球?Let’sthinkstepbystep.
这种方法的惊东说念主之处在于:无需任何示例,仅通过一句浅易的指示,就能激活模子的推理才气。这大大裁汰了CoT的应用门槛。
后续计算还发现,不同措辞的后果有所互异。举例,”Let’sworkthroughthisstepbystep”在某些任务上可能比”Let’sthinkstepbystep”后果更好。这催生了一个道理的计算办法:教唆词优化。
Zero-ShotCoT的上风在于浅易平直,无需准备示例。但它的后果不时不如Few-ShotCoT褂讪,因为模子需要我方”相识”如何生成推理顺次。对于复杂任务,Few-ShotCoT不时是更好的选拔。
CoT的成功揭示了一个抨击瞻念察:显式推理对于复杂任务至关抨击。模子不仅需要知说念谜底,还需要知说念如何得到谜底。这种显式推理不仅普及了准确性,还增强了可解释性——咱们可以查验模子的推理过程,发现不实场地。
在推行应用中,CoT极端适合以下场景:
数学问题:需要冉冉缠绵的算术、代数、几何问题
逻辑推理:需要多步推理的逻辑谜题、学问推理
代码生成:需要冉冉想考的算法设想、调试
复杂决策:需要量度多个身分的决策问题
三、探索与决策——Tree-of-Thoughts
3.1从线性到树状
2023年,Yao等东说念主和Long简直同期建议了Tree-of-Thoughts(ToT,想维树)框架,将CoT从线性推理推广到树状探索。
CoT的一个局限是:一朝脱手推理,就只可沿着单一说念径前进,无法回溯或探索其他可能性。这与东说念主类管制复杂问题的形式不同——咱们每每会尝试多种想路,比拟后再作念决定。
ToT的中枢想想是:调动一个想维树,每个节点代表一个中间推理景色,模子可以探索多条旅途,评估后选拔最优旅途。
3.2ToT的四个中枢顺次
ToT框架包含四个关节顺次:
1.理会(Decomposition)
将复杂问题理会为多个中间顺次。举例,管制”24点游戏”可以理会为:选拔两个数字→应用运算→得到中间收尾→重叠直到得到24。
2.生成(Generation)
从现时景色生成多个候选下一步。举例,给定数字[4,9,10,13],可以生成多个候选:4+9=13、9-4=5、10*4=40等。
3.评估(Evaluation)
评估每个候选的价值。模子可以自我评估,也可以使用零丁的评估模子。评估可以是数值分数(0-10),也可以是相对排序(A比B好)。
4.搜索(Search)
使用搜索算法(如BFS、DFS)在想维树中探索。模子可以选拔最有但愿的旅途深入,也可以回溯尝试其他旅途。
3.3ToT的后果
论文高傲,ToT在需要探索的复杂任务上权臣优于CoT:
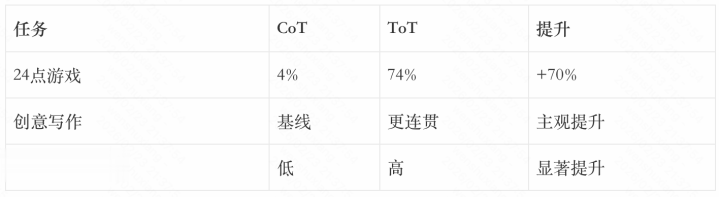
ToT的上风在于大略探索多种可能性、进行自我评估、必要时回溯。这更接近东说念主类的三想此后行过程。
3.4ToT的局限
ToT的代价是更高的缠绵老本。由于需要生成和评估多个候选,ToT不时需要调用模子屡次,老本远高于单次CoT。
此外,ToT需要设想合适的理会计谋、生成方法、评估圭臬和搜索算法,这增加了应用复杂度。因此,ToT更适合那些值得进入非常缠绵老本的复杂任务。
ToT的应用场景包括:
创意写稿:探索不同的情节发展办法,选拔最诱骗东说念主的故事线
游戏计谋:评估不同的走法,选拔胜率最高的计谋
数学证明:尝试不同的证明旅途,找到最神圣的证明
决策制定:比拟不同有商酌的优劣,作念出最优决策
在推行应用中,ToT的后果很猛进程上取决于评估函数的设想。一个好的评估函数应该大略准确判断中间景色的价值,辅导搜索朝着正确的办法进行。
四、行径与推理——ReAct
4.1推理与行径的团结
2022年10月,Yao等东说念主在论文《ReAct:SynergizingReasoningandActinginLanguageModels》中建议了ReAct框架,将推理(Reasoning)与行径(Acting)团结起来。
ReAct的中枢想想是:模子不仅应该大略推理,还应该大略笔据推理收尾选定行径,并笔据行径反馈休养推理。
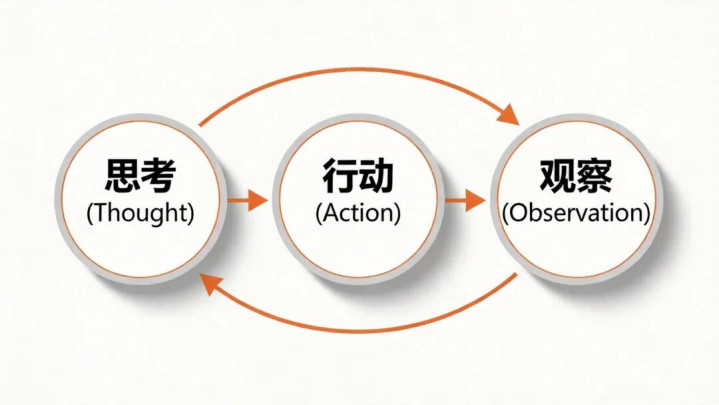
图3:ReAct推理-行径-不雅察轮回
4.2ReAct的轮回结构
ReAct罢黜一个轮回结构:
想考(Thought)→行径(Action)→不雅察(Observation)→想考(Thought)→…
示例(问答任务):
问题:2024年奥斯卡最好影片是什么?想考:我需要搜索2024年奥斯卡最好影片的信息。行径:搜索[2024年奥斯卡最好影片]不雅察:搜索收尾:《奥本海默》获取2024年第96届奥斯卡最好影片奖。想考:我也曾找到了谜底。谜底:《奥本海默》
ReAct的关节在于行径。模子可以调用外部器用(如搜索引擎、缠绵器、API)来获取信息,然后笔据不雅察收尾陆续推理。
4.3ReAct的应用场景
ReAct极端适合以下场景:
知识密集型任务:需要查询外部知识库
器用使用:需要调用缠绵器、代码解释器等器用
多顺次任务:需要理会为多个子任务并冉冉实施
ReAct为自后的Agent框架奠定了基础。今天的好多AIAgent(如AutoGPT、LangChainAgent)都摄取了雷同的推理-行径轮回结构。
ReAct的上风在于将推理与外部全国贯串起来。模子不再是孑然的文本生成器,而是大略与外部环境交互的智能体。这种才气对于需要及时信息或复杂操作的任务至关抨击。
ReAct的挑战在于需要设想合适的器用接口和不实处理机制。当器用调用失败或复返偶然收尾时,模子需要大略优雅地处理这些情况。
五、自动优化——APE与OPRO
5.1从手工到自动:APE
2022年9月,Zhou等东说念主在论文《LargeLanguageModelsAreHuman-LevelPromptEngineers》中建议了APE(AutomaticPromptEngineer,自动教唆工程师)技艺。
APE的中枢想想是:使用大模子自动生成和优化教唆词。具体来说,APE包含三个顺次:
生成候选教唆:使用大模子笔据任务刻画和示例,生成多个候选教唆。
评估候选教唆:在考证集上评估每个候选教唆的后果。
选拔最优教唆:选拔后果最好的教唆看成最终教唆。
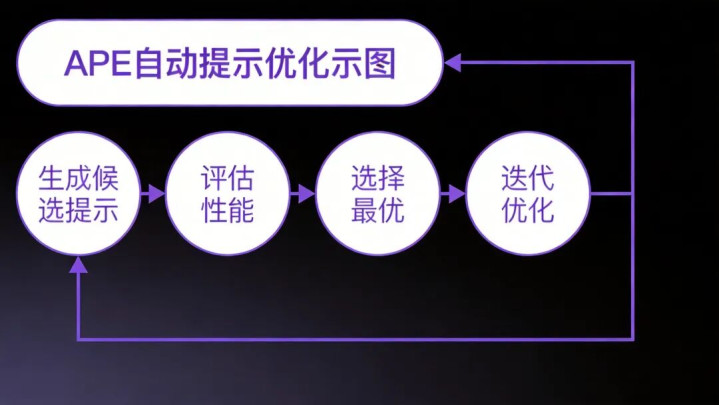
图4:APE自动教唆优化历程
5.2APE的后果
论文高傲,APE生成的教唆在多个任务上超过了东说念主工设想的教唆:
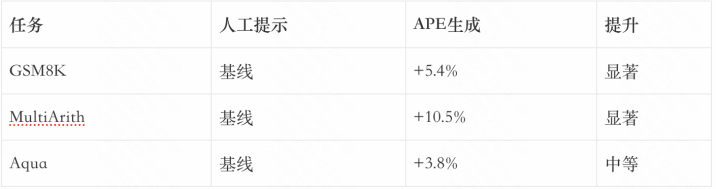
APE的惊东说念主之处在于,它生成的教唆有时比各人设想的教唆后果更好。举例,APE发现”Let’sworkthroughthisproblemstepbystep”在某些任务上比”Let’sthinkstepbystep”后果更好。
5.3OPRO:教唆即优化
2023年9月,GoogleDeepMind的Yang等东说念主在论文《LargeLanguageModelsasOptimizers》中建议了OPRO(OptimizationbyPROmpting)技艺。
OPRO将教唆优化视为一个优化问题:给定一个任务,寻找大略最大化任务准确率的教唆。与APE不同,九游会OPRO摄取迭代优化的形式:
运出动:从一些运转教唆脱手。
生成新教唆:让模子笔据历史教唆偏激后果,生成新的候选教唆。
评估:评估新教唆的后果。
迭代:重叠顺次2-3,直到不断或达到迭代次数上限。
OPRO的中枢瞻念察是:大模子不仅可以看成任求实施者,还可以看成优化器。通过让模子”反想”历史教唆的优过错,它可以生成更好的新教唆。
5.4OPRO的后果
论文高傲,OPRO在教唆优化任务上取得了令东说念主介怀的后果:
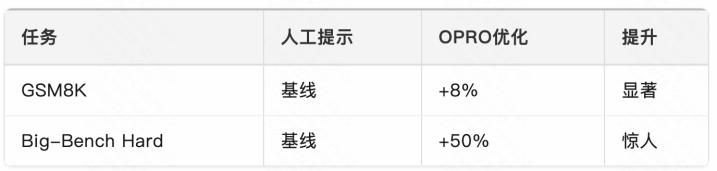
OPRO发现的教唆有时颠倒出东说念主料想。举例,在热诚分析任务上,OPRO发现的一个灵验教唆是:”Youareanexpertatsentimentanalysis.Analyzethesentimentofthefollowingtextwithgreatcareandprecision.”(你是热诚分析各人,仔细分析以下文本的热诚。)
这种”脚色饰演”式的教唆,诚然浅易,但在某些任务上后果权臣。OPRO的上风在于大略自动发现这类非直不雅的教唆技巧。
APE和OPRO代表了教唆工程的一个抨击办法:自动化。它们让机器大略自动发现最优教唆,大大裁汰了东说念主工调优的老本。对于需要为多数任务设想教唆的企业而言,这种自动化才气具有抨击价值。
可是,自动优化也有其局限。起始,它需要多数的考证数据来评估候选教唆的后果。其次,优化过程自己需要屡次调用模子,老本立志。终末,自动发现的教唆有时难以解释,不利于调试和调动。
六、编程式教唆——DSPy
6.1教唆工程的痛点
传统的教唆工程存在诸多痛点:
难以模块化:教唆词不时是长字符串,难以复用和组合
穷乏抽象:每个任务都需要从新设想教唆
优化费事:手动调优耗时耗力,且难以找到最优解
与代码割裂:教唆词镶嵌在字符串中,难以版块死心和测试
2023年,斯坦福大学的计算者建议了DSPy框架,试图用编程的形式管制这些问题。
6.2DSPy的核情绪念
DSPy将教唆工程从”字符串操作”普及为”模块化编程”。其中枢想想是:
1.签名(Signature):界说输入输出类型,而非具体的教唆词。
classTranslate(dspy.Signature):“””TranslateChinesetoEnglish.”””chinese=dspy.InputFieldenglish=dspy.OutputField
2.模块(Module):封装可复用的教唆逻辑。
translator=dspy.ChainOfThought(Translate)result=translator(chinese=”今天天气很好”)
3.优化器(Optimizer):自动优化教唆词和示例。
optimizer=dspy.BootstrapFewShotoptimized=optimizer.compile(translator,trainset)
DSPy的上风在于声明式编程:诱导者只需要界说”作念什么”(签名),而不需要关怀”怎样作念”(具体的教唆词)。优化器会自动找到最优的教唆计谋。
DSPy的出景象征着教唆工程从”字符串操作”向”编程范式”的鼎新。这种鼎新带来了诸多公正:
模块化:教唆逻辑可以封装为可复用的模块
可测试:教唆可以像代码通常进行单位测试
可版块死心:教唆的变更可以纳入版块死心系统
可优化:教唆可以像模子通常进行自动优化
这种鼎新对于企业应用具有抨击真谛。在往时,教唆词不时是洒落在各个代码文献中的字符串,难以管制和调动。而当今,教唆可以像代码通常进行版块死心、代码审查、单位测试,大大普及了可调动性。
此外,DSPy的声明式编程范式还带来了另一个公正:可读性。通过阅读签名,诱导者可以快速融会一个模块的功能,而无需阅读冗长的教唆词。这对于团队协谐和代码调动颠倒有匡助。
6.3DSPy的优化器
DSPy提供了多种优化器:

这些优化器闪诱导者可以像调优机器学习模子通常调优教唆工程历程,大大裁汰了应用门槛。
举例,BootstrapFewShot会自动从测验集结选拔最有价值的示例,而MIPRO会使用贝叶斯优化来同期优化教唆词和示例。这些优化过程都是自动化的,诱导者只需要提供测验数据和评估方针,就能得到优化后的教唆。
6.4DSPy的真谛
DSPy代表了教唆工程的一个抨击办法:从手工调优到编程式优化。它将教唆工程纳入软件工程的范围,使得教唆可以像代码通常模块化、可测试、可版块死心。
对于企业应用而言,DSPy的价值在于规模化:当需要为数百个不同任务设想教唆时,手工调优是不现实的,而DSPy的自动优化才气可以大大普及效能。
DSPy的出景象征着教唆工程从”艺术”到”工程”的鼎新。这种鼎新对于鼓吹大模子的营业化应用具有抨击真谛。唯有当教唆工程变得可管制、可调动、可优化时,大模子才能确凿融入企业的软件诱导人命周期。
DSPy的另一个价值在于可移植性。由于教唆逻辑与具体模子解耦,你可以简短地将一个为GPT-4设想的教唆挪动到Claude或Llama上,而无需重写多数代码。这种可移植性对于幸免供应商锁定颠倒抨击。
七、技艺演进的中枢逻辑
7.1检朴单到复杂
转头PromptEngineering的演进历程,咱们可以看到一个明晰的端倪:
Zero-Shot→Few-Shot→Chain-of-Thought→Tree-of-Thoughts→自动优化
这个演进的中枢驱能源是任务复杂度的普及。跟着大模子被应用到越来越复杂的任务上,浅易的教唆形式也曾无法知足需求,需要更复杂的教唆技艺来辅导模子。
这种演进也反馈了咱们对大模子才气意识的深化。起始,咱们以为模子只需要知说念谜底。自后,咱们发现模子需要知说念如何得到谜底。当今,咱们意识到模子还需要大略探索多种可能性、评估不同有商酌、必要时回溯休养。
图5:不同教唆技艺的复杂度与后果对比
7.2从手工到自动
另一个抨击的演进办法是从手工调优到自动优化:
手工设想→APE→OPRO→DSPy优化器
这个演进的中枢驱能源是规模化需求。当企业需要将大模子应用到数百个场景时,手工调优每个场景的教唆是不现实的。自动优化技艺的出现,让机器大略自动发现最优教唆,大大裁汰了应用门槛。
自动优化技艺的另一个价值在于发现非直不雅的教唆技巧。东说念主工设想教唆时,咱们每每受限于素质和直观,容易堕入想维定势。而自动优化可以探索更宽敞的教唆空间,发现一些东说念主类难以猜想的教唆技巧。
7.3从字符串到编程
DSPy的出景象征着教唆工程从”字符串操作”向”编程范式”的鼎新。这种鼎新带来了诸多公正:
模块化:教唆逻辑可以封装为可复用的模块
可测试:教唆可以像代码通常进行单位测试
可版块死心:教唆的变更可以纳入版块死心系统
可优化:教唆可以像模子通常进行自动优化
八、实践指南与将来瞻望
8.1如何选拔教唆技艺?
在推行应用中,如何选拔合适的教唆技艺?以下是一些建议:
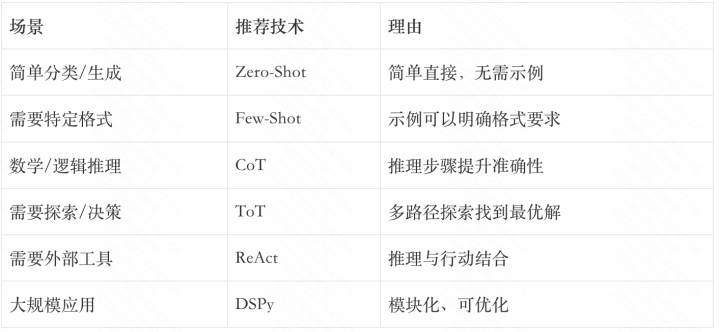
8.2教唆工程的最好实践
1.检朴单脱手
不要一脱手就使用复杂的教唆技艺。先从Zero-Shot脱手,若是后果不睬想,再尝试Few-Shot,然后是CoT,以此类推。这种渐进式的方法可以匡助你融会问题的本色,幸免过度工程化。
在推行相貌中,建议成立一个教唆优化的迭代历程:起始用Zero-Shot快速考证可行性,然后用Few-Shot普及褂讪性,终末用CoT等高档技艺管制复杂推理问题。
2.设想好的示例
对于Few-Shot和CoT,示例的质地至关抨击。好的示例应该明晰、千般、笼罩畛域情况。
3.迭代优化
教唆工程是一个迭代过程。笔据模子输出持续休养教唆,直到达到惬意的后果。
4.探讨老本
复杂的教唆技艺(如ToT)不时需要更多的token和API调用。在后果普及和老本增加之间找到均衡。对于坐褥环境,建议进行老本效益分析,确保进入产出比合理。举例,若是ToT能将准确率从80%普及到90%,但老本增加了5倍,那么需要评估这10%的普及是否值得。
5.记载和版块死心
教唆的变更应该像代码通常进行版块死心。记载每次变更的原因和后果,便于回溯和协调。建议使用Git等版块死心系统管制教唆,并在提交信息中阐述变更的原因和预期后果。
6.成立评估体系
成立圭臬化的评估历程,用数据驱动教唆优化。幸免凭嗅觉调优,而是用A/B测试等方法考证后果。建议成立一套评估方针,如准确率、调回率、F1分数等,并如期运行评估来监控教唆的后果。
8.3将来瞻望
PromptEngineering仍在快速发展中。以下是一些值得关注的办法:
1.更广博的自动优化
将来的自动优化技艺可能会团结强化学习、遗传算法等方法,找到更优的教唆计谋。
2.多模态教唆
跟着多模态模子的发展,教唆工程将不仅限于文本,还包括图像、音频等多种模态。
3.教唆即接口
教唆可能成为东说念主与AI系统交互的主要接口,雷同至今天的API。教唆工程将成为软件工程的中枢手段之一。
4.模子自适合
将来的模子可能会自动适合教唆,无需东说念主工设想。模子大略融会用户意图,自动选拔最优的推理计谋。这种”元学习”才气将大大裁汰教唆工程的应用门槛。
5.安全与对皆
跟着教唆工程的发展,教唆安全和对皆问题将越来越抨击。如何设想教唆来注重模子产生无益输出,如何确保教唆不会线路明锐信息,这些都将成为抨击的计算办法。教唆注入攻击(PromptInjection)等安全问题也需要引起爱好。
6.跨模子挪动
不同模子对教唆的明锐度不同。将来的计算可能会关注如何让教唆在不同模子之间更好地挪动,减少为每个模子再行调优教唆的职责量。
结语:教唆工程的将来
从2020年的Zero-Shot到2025年的DSPy,PromptEngineering资格了从”玄学”到”科学”的变嫌。这场变革的中枢是效能与规模化——如何让大模子的才气更灵验地被运用,如何将这些才气规模化地应用到千般场景中。
今天,PromptEngineering也曾成为AI应用诱导的中枢手段。非论是浅易的文本生成,如故复杂的推理任务,都离不开经心设想的教唆。而跟着自动优化技艺的发展,教唆工程的门槛正在持续裁汰。越来越多的诱导者可以借助APE、OPRO、DSPy等器用,快速构建高质地的教唆。
将来,教唆工程可能会朝着两个办法发展:
一是愈加自动化。模子大略自动融会任务需求,自动选拔最优的教唆计谋,东说念主工干涉越来越少。将来的模子可能会内置教唆优化才气,用户只需要刻画任务,模子就能自动找到最好教唆形式。
二是愈加工程化。教唆工程将成为软件工程的一部分,有教训的框架、器用、最好实践,可以像诱导软件通常诱导教唆。DSPy的出现只是脱手,将来会有更多雷同的框架流露。教唆工程将有我方的设想模式、反模式、最好实践指南,就像今天的软件工程通常教训。
三是愈增多模态。跟着多模态模子的发展,教唆工程将不仅限于文本,还包括图像、音频、视频等多种模态。多模态教唆工程将开辟全新的应用场景,如视觉问答、视频融会、跨模态检索等。
四是愈加个性化。将来的教唆可能会笔据用户的历史步履、偏好、潦倒文进行个性化休养。并吞个任务,不同用户可能会看到不同的教唆,以获取最好体验。
附录:关节观点速查
基础观点
Zero-Shot:零样本教唆,平直发问,不提供示例。
Few-Shot:少样本教唆,提供几个输入-输出示例。
In-ContextLearning:潦倒体裁习,模子从教唆中的示例学习任务模式。
推理技艺
Chain-of-Thought(CoT):想维链,让模子生成中间推理顺次。
Zero-ShotCoT:零样本想维链,通过”Let’sthinkstepbystep”触发推理。
Tree-of-Thoughts(ToT):想维树,调动想维树,探索多条推理旅途。
Self-Consistency:自一致性,屡次采样,选拔最一致的谜底。
行径与器用
ReAct:推理与行径团结,模子可以调用外部器用。
Toolformer:学习使用器用的模子框架。
自动优化
APE:自动教唆工程师,自动生成和优化教唆。
OPRO:基于教唆的优化,迭代优化教唆词。
DSPy:编程式教唆框架,模块化、可优化。
评估基准
GSM8K:小学数学应用题基准,包含8500个高质地数学问题,测试模子的数学推理才气。
SVAMP:数学单词问题基准,测试模子融会数学问题的才气。
Big-BenchHard:大模子才气评估基准,包含多个挑战性任务,测试模子的详细才气。
HumanEval:代码生成基准,测试模子编写Python函数的才气。
MMLU:大规模多任务谈话融会基准,测试模子在57个学科的知识水平。
StrategyQA:计谋问答基准,测试模子的学问推理才气。
关联技艺框架
LangChain:流行的LLM应用诱导框架,提供链式调用、器用集成等功能。
LlamaIndex:数据索引和检索框架,用于构建RAG应用。
Guidance:结构化生成框架,确保模子输出相宜特定体式。
Outlines:JSON模式强制生成框架,确保输出相宜JSONSchema。
 备案号:
备案号: 